파이썬 SW문제해결 기본 - LIST 1
01 알고리즘 02 리스트

01. 알고리즘
① 알고리즘 개요
▣ 알고리즘이란?
- 유한한 단계를 통해 문제를 해결하기 위한 절차나 방법
▣ 알고리즘 표현법
- 슈도 코드 : 일반적인 언어 코드를 흉내 내어 알고리즘을 써 놓은 코드

- 순서도 : 프로그램이나 작업의 진행 흐름을 순서에 따라 여러 가지 기호나 문자로 나타낸 도표
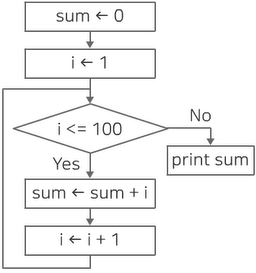
② 알고리즘의 성능 분석
▣ 무엇이 좋은 알고리즘인가?
- 정확성 : 얼마나 정확하게 동작하는가?
- 작업량 : 얼마나 적은 연산으로 원하는 결과를 얻어내는가?
- 메모리 사용량 : 얼마나 적은 메모리를 사용하는가?
- 단순성 : 얼마나 단순한가?
- 최적성 : 더 이상 개선할 여지없이 최적화되었는가?
▣ 시간 복잡도 ≒ 빅-오(O) 표기법
- 시간 복잡도 함수(실행되는 명령문의 수 계산하는 함수) 중에서 가장 큰 영향력을 주는 n에 대한 항만을 표시
- 계수는 생략하여 표기
- O(1) < O(logn) < O(n) < O(nlogn) < O(n^2) < O(2^n) < O(n!)
EX1) O(2n+1) => O(2n) => O(n)
EX2) O(2n^2+10n+100) => O(n^2)
EX3) O(4) => O(1)
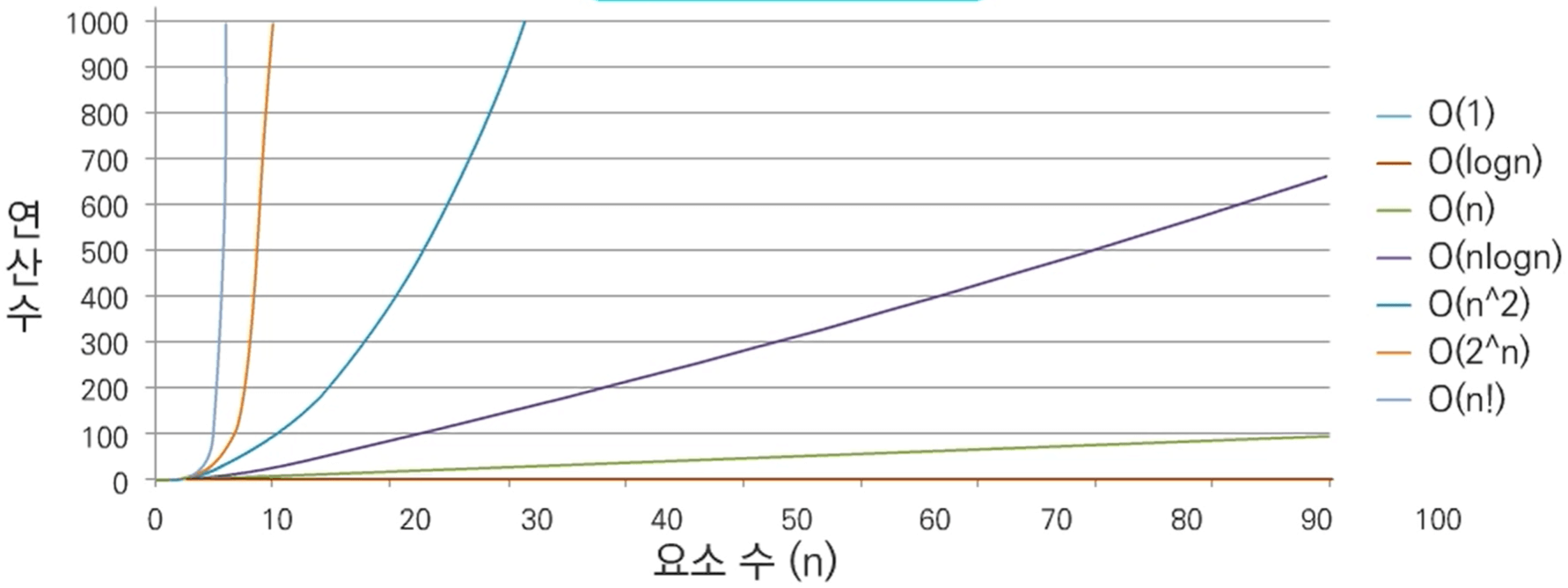
개인적으로 시간 복잡도 개념이 중요해 보인다. 일반적으로 원하는 기능을 수행하는 알고리즘을 설계하는 것은 기본적인 사항이다. 그것의 효율성을 계산하는 것, 그리고 더욱 효율적으로 업데이트하는 것이 더욱 중요하다.
02. List
① Python 소개
▣ 파이썬(Python)
- 파이썬은 프로그램 실행 속도가 느리다. 하지만 프로그램 개발 속도가 빠르다.
▣ 변수
- 파이썬에서 모든 자료는 '객체' (Java나 C의 기본형 타입 변수도 '객체')
- 변수의 선언은 따로 없음 (변수에 값을 초기화 시 변수가 메모리에 생성)
- 하나의 변수에 다른 타입의 값을 저장할 수 있음 (a=1 이후 a='abc' 가능)
▣ 자료형
| 타입 | type() | 리스트 | list |
| 정수 | int | 사전 | dict |
| 실수 | float | 셋 | set |
| 복소수 | complex | None | NoneType |
| 부울 | bool | 함수 | function |
| 문자열 | str | 클래스 | 클래스명 |
| 튜플 | tuple |
| 기호 | 순서 | 중복 | 데이터변경 | 비고 | |
| tuple | () | O | O | X | 수의 나열은 tuple로 인식 packing, unpacking |
| list | [] | O | O | O | |
| dictionary | {} | X | 키의 중복 : X 값의 중복 : O |
O | {키: 값}의 구조로 저장 키는 불변 객체만 |
| set | {} | X | X | O | 불변 객체만 저장 가능 |
② List 소개
▣ 배열(List)
- 같은 타입 변수들을 하나의 이름으로 열거하여 사용하는 자료구조
- 파이썬의 리스트는 C나 Java에서의 배열과 '비슷한' 자료구조(아래 배열과 리스트의 차이점 참조)
③ List 사용법
▣ 파이썬의 변수
- 별도의 선언을 요구하지 않으며 변수에 값을 할당할 때 자동으로 생성
- 만약 미리 선언이 필요하다면 값을 할당해두면 됨 (sum = 0, num = [], arr = list())
▣ 배열과 리스트의 차이점
- 배열 : 같은 타입의 데이터만 저장, 처음 크기를 지정한 후 변경할 수 없음
- 리스트 : 다양한 타입의 데이터 저장, 처음 크기를 지정한 후 가변적으로 변경 가능
▣ 시퀀스(Sequence) 자료형
- '순서'가 존재함으로, 인덱싱과 슬라이싱 연산 모두 적용 가능
- 인덱싱(Indexing) : 시퀀스 자료형에서 하나의 요소를 인덱스를 통해 참조
arr = ['a', 'b', 'c', 'd', 'e', 'f']
arr[0] #'a' 첫 번째 요소
arr[2] #'c' 세 번째 요소
arr[-1] #'f' 뒤에서 첫 번째 요소
- 슬라이싱(Slicing) : 시퀀스 자료형의 원하는 범위를 선택하는 연산
arr = ['a', 'b', 'c', 'd', 'e', 'f']
arr[1:3] #['b', 'c'] (1 이상 3 미만)
arr[:3] #['a', 'b', 'c'] (처음부터 3 미만까지)
arr[1:] #['b', 'c', 'd', 'e', 'f'] (1 이상부터 마지막까지)
arr[:] #['a', 'b', 'c', 'd', 'e', 'f'] (처음부터 마지막까지)
▣ 함수와 연산
| 함수 | 설명 | 예시 | 결과 |
| len() | 원소 개수 | len([1,3,5]) | 3 |
| + | 시퀀스 연결 | [1,2,3] + [4,5] | [1,2,3,4,5] |
| * | 반복 | [1,2] * 2 | [1,2,1,2] |
| in | 소속하는가 | 2 in [1,2,3] | True |
| not in | 소속하지 않는가 | 2 not in [1,3] | True |
| min() | 원소 중 최소값 | min([3,5,2]) | 2 |
| max() | 원소 중 최대값 | max([3,5,2]) | 5 |
| sorted() | 정렬된 리스트 반환 | print(sorted([3,5,2])) | [2,3,5] |
▣ 리스트 함축(List Comprehension)
- 수학에서 집합을 정의하는 표현식과 유사함
- 반복문, 조건문을 중첩하여 사용 가능
mylist = [1,2,3,4,5,6]
newlist = [i for i in mylist if i%2==0] #[2,4,6]
'SWEA() > Intermediate_Learn' 카테고리의 다른 글
| [SWEA]4828. 파이썬 SW문제해결 기본 - LIST 1 : min max (0) | 2021.10.17 |
|---|---|
| [SWEA]파이썬 SW문제해결 기본 - LIST 1 : Sort(정렬)-카운팅 정렬 (0) | 2021.10.16 |
| [SWEA]파이썬 SW문제해결 기본 - LIST 1 : Sort(정렬)-버블 정렬 (0) | 2021.10.15 |
| [SWEA]파이썬 SW문제해결 기본 - LIST 1 : Greedy Algorithm (0) | 2021.10.13 |
| [SWEA]파이썬 SW문제해결 기본 - LIST 1 : Exhaustive Search(완전 탐색) (0) | 2021.10.12 |